Welcome to the website of the one-day workshop “Regularisation for Inverse Problems and Machine Learning”, which will be held at the Campus Jussieu (room 16-26-209) in Paris on November 19th 2019.
The Workshop is now done, thanks to everyone participating. All the slides of the presentations are available, see the program below.
What is this workshop about
The purpose of the workshop is to gather together people working on problems arising in different fields such as imaging, machine learning and inverse problems theory in order to underline similarities and differences of the regularisation approaches used (Tikhonov, early stopping, implicit regularization…).
Program
All the talks will be held in the room 16-26-209. Coffee breaks and lunch will be organized in the room 15-25-202.
- 09h45-10h15 Welcome Coffee


- 10h15-11h00 Talk by Martin Benning (Queen Mary University of London)
Title: Deep learning as optimal control problems
Slides: link
Abstract: (click to unroll)
We consider recent works where deep neural networks have been interpreted as discretisations of an optimal control problem subject to an ordinary differential equation constraint. We review the first order conditions for optimality, and the conditions ensuring optimality after discretisation. This leads to a class of algorithms for solving the discrete optimal control problem which guarantee that the corresponding discrete necessary conditions for optimality are fulfilled. The differential equation setting lends itself to learning additional parameters such as the time discretisation. We explore this extension alongside natural constraints (e.g. time steps lying in a simplex) and compare these deep learning algorithms numerically in terms of induced flow and generalisation ability. We conclude by addressing the interpretation of this extension as iterative regularisation methods for inverse problems. This is joint work with Elena Celledoni, Matthias J. Ehrhardt, Brynjulf Owren and Carola-Bibiane Schönlieb.
- 11h00-11h45 Talk by Silvia Villa (Universitá di Genova)
Title: Stability and regularization properties of diagonal proximal gradient methods
Slides: link
Abstract: (click to unroll)
Many applied problems in science and engineering can be modeled as noisy inverse problems. Tackling these problems requires to dealwith their possible ill-posedness and to devise efficient numerical procedures to quickly and accurately compute a solution. In this context, Tikhonov regularization is a classical approach. A solution is defined by the minimization of an objective function beingthe sum of two terms: a data-fit term and a regularizer ensuring stability. However, in practice, finding the best Tikhonov regularized solutionrequires specifying a regularization parameter determining the trade-off between data-fit and stability. From a numerical perspective, this can dramatically increase the computational costs to find a good solution. In this talk, I will present an alternative approach based on iterative regularization techniques. The latter are classical regularization methods basedon the observation that stopping an iterative procedure corresponding to the minimization of an empirical objective has a self-regularizing property. Crucially, the number of iterations becomes the regularization parameter, and hence controls at the same time the accuracy of the solution as well as the computational complexity of the method, making parameter tuning numerically efficient and iterative regularization an alternative to Tikhonov regularization. I will present general iterative regularization methods allowing to consider large classes of data-fit terms and regularizers, based on proximal and gradient descent steps. The proposed analysis establishes convergence as well as stability results.
- 11h45-12h30 Talk by Martin Burger (FAU Erlangen-Nürnberg)
Title: Implicit regularization in machine learning: a perspective from iterative regularization theory
Slides: link
Abstract: (click to unroll)
In this talk we will approach the implicit regularization properties found when applying (stochastic) gradient descent to empirical risk minimization problems ( e.g. in deep learning) with the paradigms of regularization theory in inverse problems. We will demonstrate the decrease of the population risk up to a specific error, which can be estimated in optimal transport metrics. We will discuss the analogy of such properties to the classical discrepancy principle in iterative regularization.
- 12h30-14h00 Lunch (Buffet)


- 14h00-14h45 Talk by Lorenzo Rosasco (LCSL, Universitá di Genova, MIT, IIT)
Title: Not so fast: learning with accelerated optimization
Slides: link
Abstract: (click to unroll)
The focus on optimization is a major trend in modern machine learning. In turn, a number of optimization solutions have been recently developed and motivated by machine learning applications. However, most optimization guarantees focus on the training error, ignoring the performance at test time which is the real goal in machine learning. In this talk, take steps to fill this gap in the context of least squares learning. We analyze the learning (test) performance of accelerated gradient methods. In particular, we discuss the influence of different learning assumptions on the corresponding rates.
- 14h45-15h30 Talk by Marie-Caroline Corbineau (CentraleSupélec, Université Paris-Saclay)
Title: Deep Unfolding of a Proximal Interior Point Method for Image Restoration
Slides: link
Abstract: (click to unroll)
Variational methods are widely applied to ill-posed inverse problems for they have the ability to embed prior knowledge about the solution. However, the level of performance of these methods significantly depends on a set of parameters, which can be estimated through computationally expensive and time-consuming methods. In contrast, deep learning offers very generic and efficient architectures, at the expense of explainability, since it is often used as a black-box, without any fine control over its output. Deep unfolding provides a convenient approach to combine variational-based and deep learning approaches. Starting from a regularized variational formulation for image restoration, we develop iRestNet, a neural network architecture obtained by unfolding a proximal interior point algorithm. Hard constraints, encoding desirable properties for the restored image, are incorporated into the network thanks to a logarithmic barrier, while the barrier parameter, the stepsize, and the penalization weight are learned by the network. We derive explicit expressions for the barrier proximity operator and its gradient for three types of constraints, which allows training iRestNet with gradient descent and backpropagation. In addition, we provide theoretical results regarding the stability of the network for a common inverse problem example. Numerical experiments on image deblurring problems show that the proposed approach compares favorably with both state-of-the-art variational and deep learning methods in terms of image quality.
- 15h30-16h00 Coffee break
- 16h00-16h45 Talk by Gilles Blanchard (Université Paris-Sud, Université Paris-Saclay)
Title: Simultaneous adaptation for several criteria using an extended Lepskii principle
Slides: link
Abstract: (click to unroll)
In the setting of supervised learning, we propose a data-dependent regularization parameter selection rule that is adaptive to the unknown regularity of the target function and is optimal both for the least-square (prediction) error and for the reproducing kernel Hilbert space (reconstruction) norm error. It is based on a modified Lepskii balancing principle using a varying family of norms.

Location
The workshop will be held at the Campus Jussieu in Paris.
| Finding Jussieu in Paris | Finding the workshop in Jussieu |
|---|---|
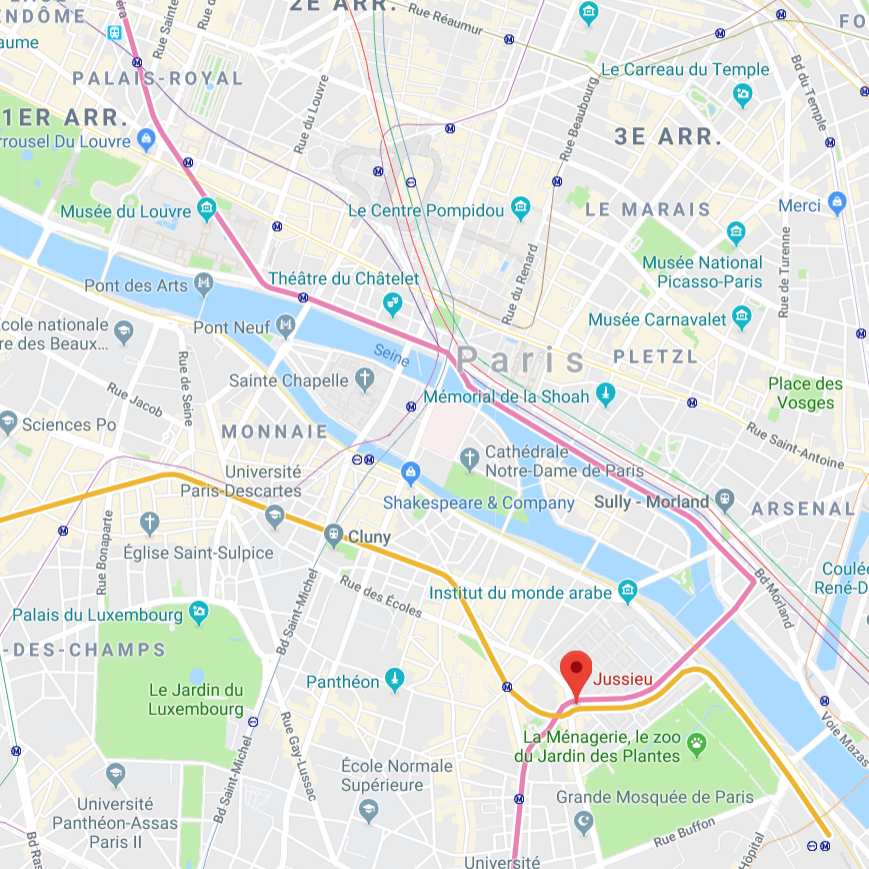 |
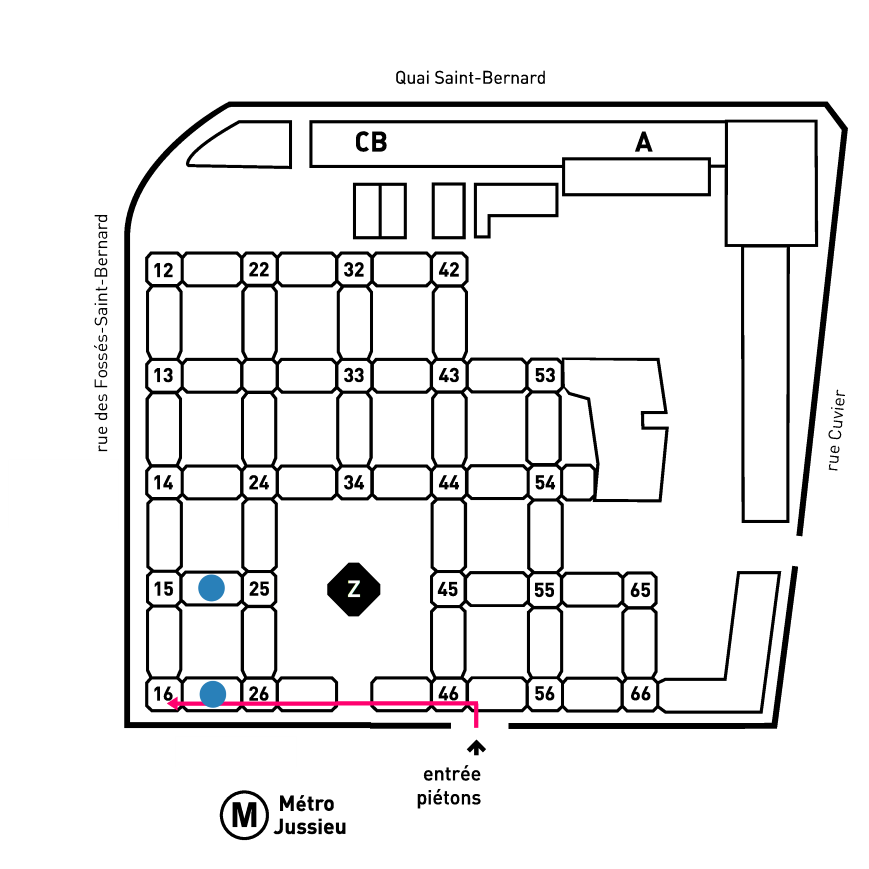 |
- Jussieu can be accessed via the Metro lines 7 and 10. Line 7 connects to the RER B (Gare du Nord, Airport Charles de Gaulle) at Châtelet.
- In Jussieu, get to the 2nd floor by taking the stairs/elevator through the (numbered) towers. Talks will be in the room 209 (between towers 16-26), coffee and lunch will be served in room 202 (15-25).
Organization
- Luca Calatroni (calatroni ‘at’ i3s.unice.fr) Chargé de Recherche (CNRS) à l’Université Nice Sophia Antipolis.
- Guillaume Garrigos (guillaume.garrigos ‘at’ lpsm.paris) Maître de Conférences à l’Université de Paris.
Support
This workshop is supported by the CNRS through the INSMI PEPS JCJC project “Efficient iterative regularization for inverse problems and machine learning” (EFIR), the GdR Mathématiques de l’Optimisation et Applications, and the Laboratoire de Probabilités, Statistiques et Modélisation.
![]()
Registration
Due to room limitations, the inscriptions are now closed.
List of Participants
| Name | Affiliation |
|---|---|
| Joseph Salmon | Université de Montpellier / IMAG |
| Jean-Luc Starck | CEA Saclay |
| Youssef EL HABOUZ | IGDR rennes |
| Paul Dufossé | INRIA/CMAP |
| Zoltan Szabo | CMAP, Ecole Polytechnique |
| Luigi Carratino | University of Genova |
| Kamelia Daudel | Telecom Paris |
| Mastane Achab | Télécom ParisTech, LTCI |
| Justin Carpentier | INRIA |
| Yury Maximov | Los Alamos National Laboratory |
| Stéphane Crépey | LaMME |
| Pascal Guehl | Laboratoire de recherche ICube |
| Samuel Vaiter | CNRS & IMB |
| Jean-David Fermanian | Crest |
| Chandrachud Basavaraj | StillMind |
| Stefano De Marco | Ecole Polytechnique |
| Dorinel Bastide | BNP Paribas |
| Lénaïc Chizat | Cnrs/LMO |
| Quentin Bertrand | INRIA |
| Ismael CASTILLO | LPSM Sorbonne Université |
| Antoine Chambaz | Université de Paris |
| Camille Pouchol | Université de Paris |
| Mathurin Massias | Inria |
| Pierre Marion | LPSM |
| Ruben OHANA | Laboratoire de Physique de l’ENS |
| Markus Schmidtchen | LJLL |
| Barbara Gris | LJLL (Sorbonne Université) |
| Zaccharie Ramzi | Inria |
| Vincent DUVAL | INRIA Paris / CEREMADE |
| Baptiste Gregorutti | Safety Line |
| Frédéric Nataf | LJLL |
| SHIJIE DONG | LJLL |
| Carole LE GUYADER | Laboratoire de Mathématiques de l’INSA Rouen Normandie |
| Marcela Szopos | MAP5, Univ. de Paris |
| EL KAROUI Nicole | LPSM Jussieu |
| Della Valle Cécile | LJLL |
| Odyssée Merveille | CREATIS / INSA |
| Pauline Tan | LJLL, Sorbonne Université |
| Bouazza SAADEDDINE | Crédit Agricole CIB - LaMME - LPSM |
| Nacime Bouziani | Imperial College London |
| Ilaria Giulini | Université Paris Diderot |
| KAI SHIMAGAKI | LCQB, Sorbonne Université |
| Laraki Rida | CNRS, PSL-Dauphine |
| Pierre-cyril Aubin-frankowski | MINES ParisTech |
| El mehdi Said | LMRS (Université de Rouen) |
| Xiaoyu Wang | University of Cambridge |